

昨天一位好友,找我帮忙写一个采集某资源站的程序。项目需求如下:
项目需求
- 采集软件详情页
- 采集软件的名称
- 采集软件的分类标签
- 采集软件的图片
- 采集软件的发布时间
- 采集软件的正文描述
项目开发周期
半天
开发思路
首先,先来看一下网页的大概布局:
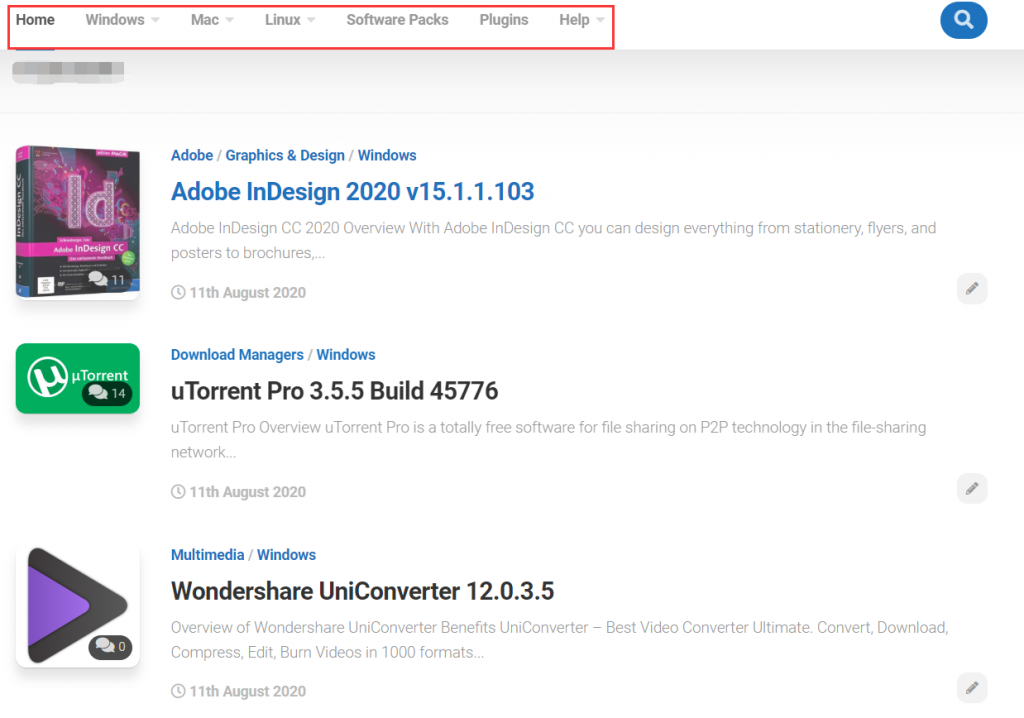
在主导航栏有软件的分类,而在首页的内容中,软件是混合在一起展示的。考虑到需求采集软件的分类标签,何不根据分类进行采集呢。
来到软件详情页:
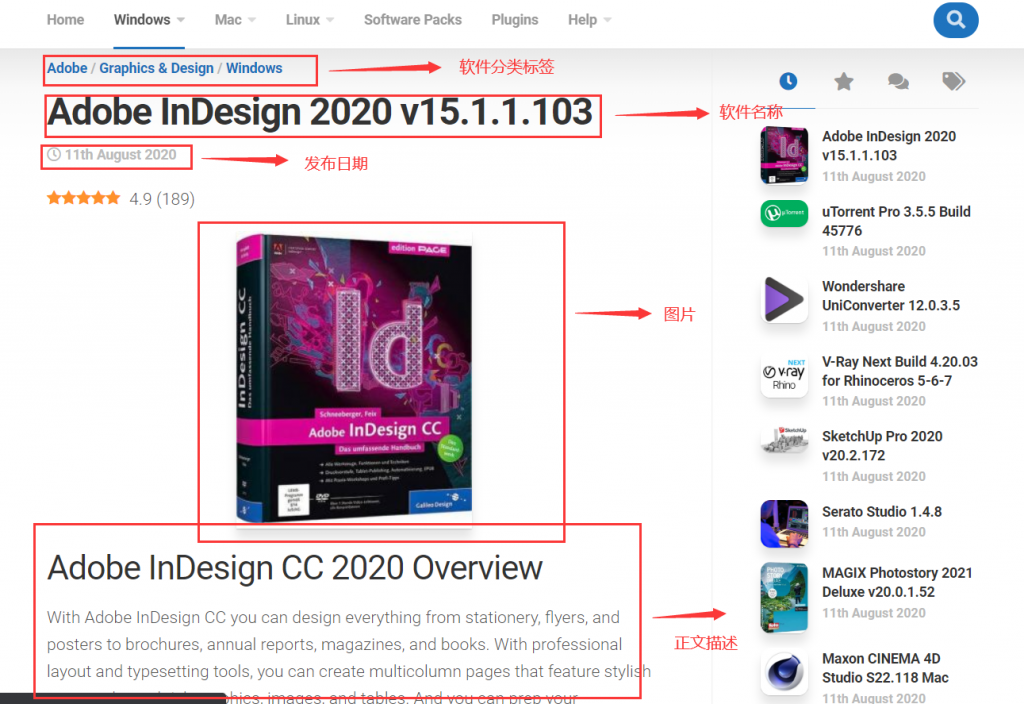
现在就看这些数据是怎么来的了?!
打开开发者工具,在异步勾选:
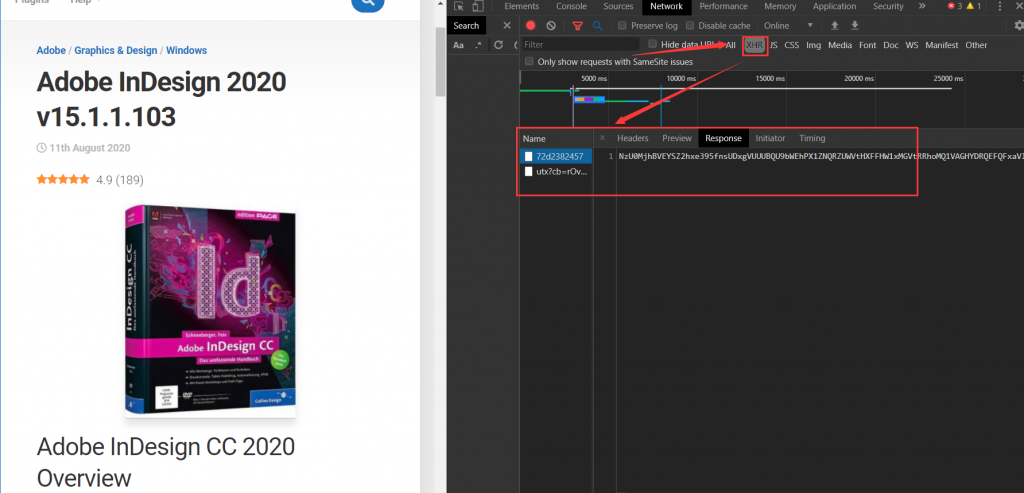
但是两个异步接口没有相关的信息返回,好吧貌似不能直接异步爬去,这给开发增加了一丝丝的难度。目前就只有一个方法:直接通过渲染好的网页进行信息抽取!也就只能这样了!
项目思路
- 根据网站分类进行分类爬取
- 在软件列表页面得到每个软件详情页的地址
- 通过请求每个软件的详情页地址来到详情页再抽取相关信息采集
开发
软件分类列表页址获取
点击windows分类:
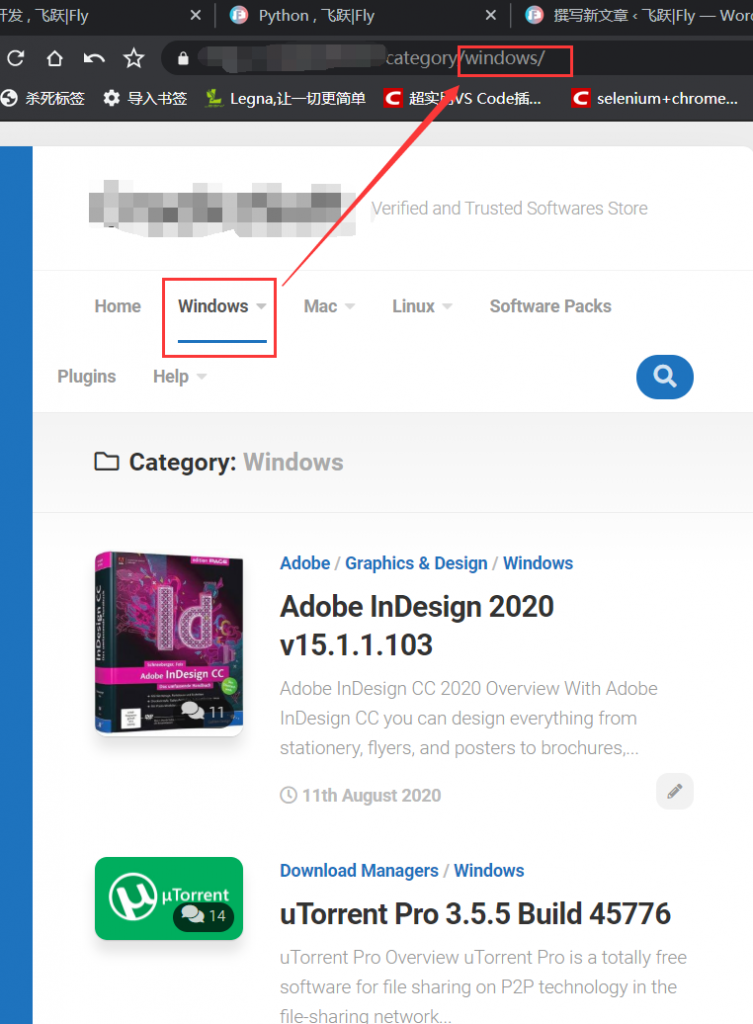
d可以看到url的变化: https://xxx.xxx/category/windows/
那么可以猜想:不同分类下的url构成 https://xxx.xxx/category/ +分类名/
这样分类采集的依据就有了。
再看每页的最下面:
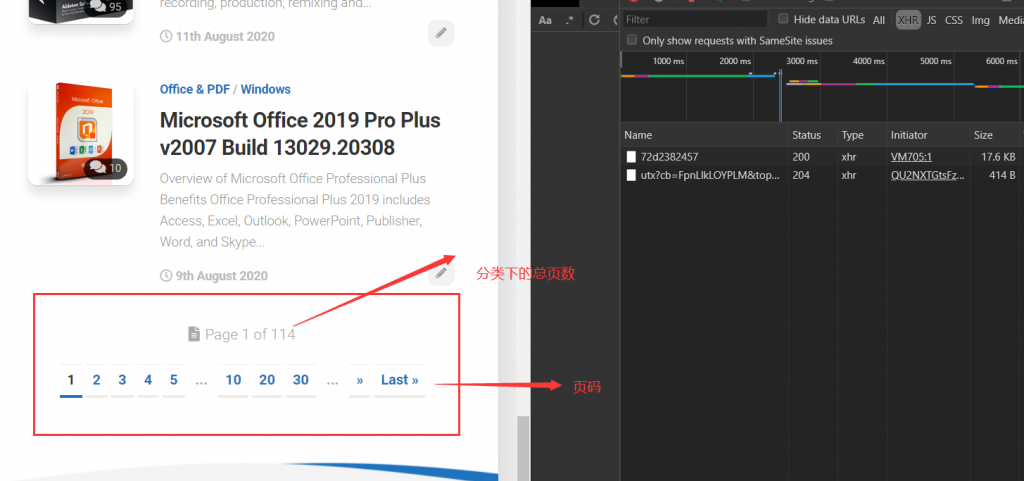
有页码和总页数的展示,看来还得实现翻页。点击第二页:
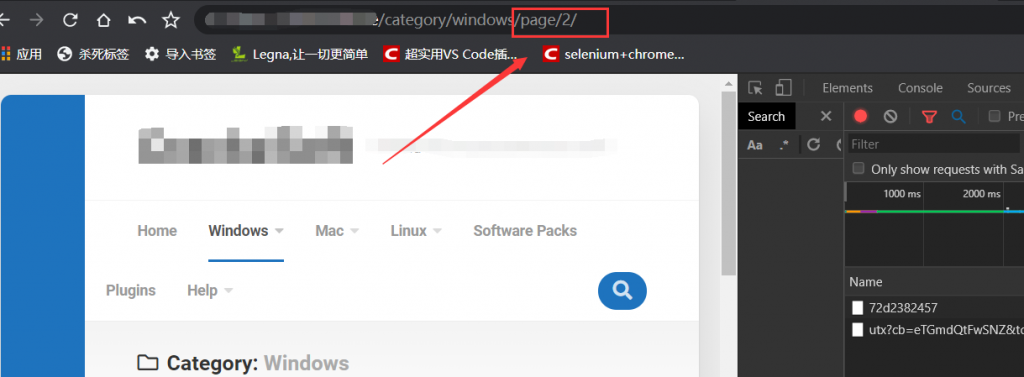
可以看到第二页的url,在分类的url基础上多了:page/page_num/。
既然这样翻页逻辑就有了: https://xxx.xxx/category/category_name/ page/page_num/
而且在每页满条目展示的情况下,自动展示9个软件条目。
下面就开始写这部分的代码。
软件分类列表页地址方法
前面提到在分类展示页面的底下有展示总页数的地方,可以抽取这部分信息截取总页数的数字:

网页解析库选择 :Beautifulsoup4
from bs4 import BeautifulSoup as bsp
import requests
base_url = 'https://xxx.xxx/category/'
category_url = base_url + category +'/'
req = requests.get(category_url) #请求构造的分类第一页
req_txt = req.text
html = bsp(req_txt,'lxml') #实例化bsp对象
info_pages= html.find_all(attrs={'class':'pages'})[0].string #匹配标签内的总页数
total_pages = info_pages.split()[3] # 截取总页数拿到总页数后生成每页的url:
page_offset = (offset for offset in range(1,int(total_pages)+1)) #这里考虑到性能的优化,采用列表解析生成器
for num in page_offset:
item_url = base_url + category + '/page/' + str(num) + '/'
yield item_url #考虑到性能优化,采用生成器函数page_url_generator
def page_url_generator(category):
category_url = base_url + category +'/'
req = requests.get(category_url)
req_txt = req.text
html = bsp(req_txt,'lxml')
info_pages= html.find_all(attrs={'class':'pages'})[0].string
total_pages = info_pages.split()[3]
page_offset = (offset for offset in range(1,int(total_pages)+1))
for num in page_offset:
item_url = base_url + category + '/page/' + str(num) + '/'
yield item_url软件详情页地址
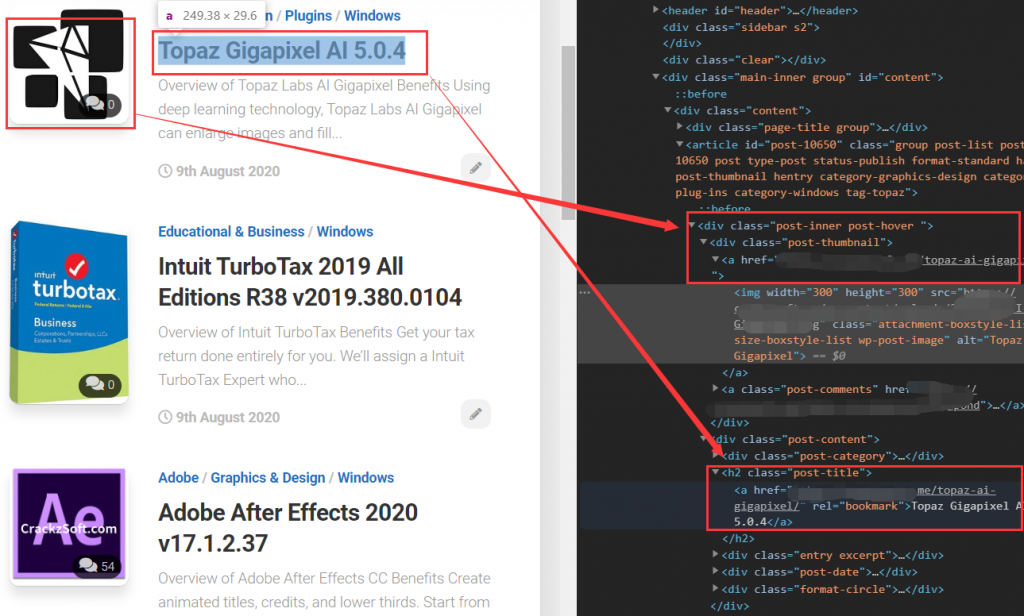
通过节点分析,软件缩略图带有详情页地址,软件标题也带有软件详情页地址。选哪个呢?!
通过xpath筛选发现:缩略图会筛选到两个地址,其中一个不符合标准。
而软件标题的地址是唯一的。那么就采用软件标题地址。
网页解析库选择:lxml
soft_url_generator
def soft_url_generator(pages_url):
for url in pages_url: #遍历传进来的 page_url_generator
req = requests.get(url)
req_text = req.text
tree_html = lxml.etree.HTML(req_text) #实例化lxml.etree.HTML对象
url_list = tree_html.xpath('//h2[@class="post-title"]/a/@href') #xpath 提取这个页面里面所有的软件详情页地址
yield url_list下面进行详情页解析,提取相应的信息。
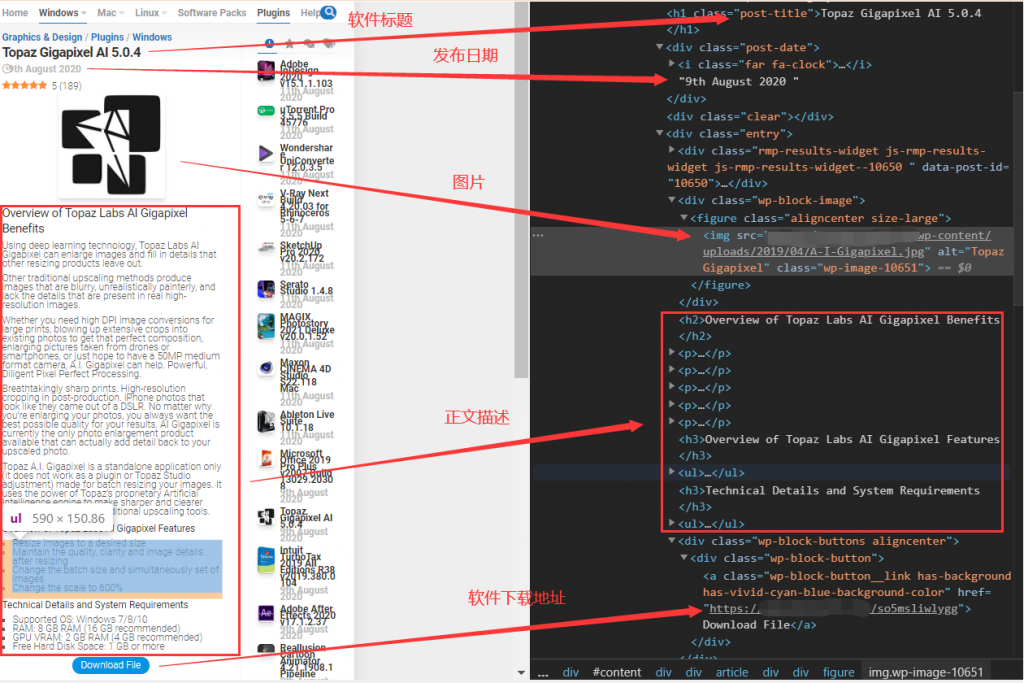
可以看到信息在相应的结点里。当我把整个详情页的解析规则写好后,我朋友却告诉我在软件下载地址那里有3种结构。看来得兼容适配其他两种,这样才会正确采集下载地址。
通过观察其他两种,发现这三种,都在不同的结点里。最后一个万能的东西该上场了,正则表达式。通过分析发现:这个下载地址在整个网页中独一无二,有着一定的特征。
在写完整个程序进行测试的时候,发现在有些软件详情页里面获取图片的时候,会报错,打开相应的网页一看,又是一种节点结构。进行兼容后又测,又报错了,没错又是一种结构,就这样兼容了5次,不知道后面还有没有,就直接写了异常捕获,进行容错。
page_parser
def page_parser(url):
detail_url = url
req = requests.get(detail_url)
req_txt = req.text
html = bsp(req_txt,'lxml')
soft_name = html.find_all(attrs={"class":"post-title"})[0].string
tree_html = lxml.etree.HTML(req_txt)
date = tree_html.xpath('//div[@class="post-date"]/text()[2]')[0]
soft_url = re.findall('https://uploadproper\.net\/\w{12}',req_txt,re.S)[0]
detail_text = tree_html.xpath('//div[@class="entry"]/p//text() | //div[@class="entry"]/h2//text() | //div[@class="entry"]/h3//text() | //div[@class="entry"]/h4//text() | //div[@class="entry"]/h5//text() | //div[@class="entry"]/ul//text()')
category = html.find_all(attrs={"rel":"category tag"})[0].string + ' / ' + html.find_all(attrs={"rel":"category tag"})[1].string
try:
img = tree_html.xpath('//figure/img/@src | //h2/img/@src | //p/img/@src | //div/img[@class="aligncenter wp-image-343 size-medium"]/@src | //p/a/img/@src')[0]
info_list = [soft_name,date,category,img,soft_url,detail_text]
except IndexError:
img = '异常导致,请自行手动获取'
info_list = [soft_name,date,category,img,soft_url,detail_text]
return info_list代码整合
import re,requests,lxml
from bs4 import BeautifulSoup as bsp
import csv
def page_url_generator(category):
category_url = base_url + category +'/'
req = requests.get(category_url)
req_txt = req.text
html = bsp(req_txt,'lxml')
info_pages= html.find_all(attrs={'class':'pages'})[0].string
total_pages = info_pages.split()[3]
page_offset = (offset for offset in range(1,int(total_pages)+1))
for num in page_offset:
item_url = base_url + category + '/page/' + str(num) + '/'
yield item_url
def soft_url_generator(pages_url):
for url in pages_url: #遍历传进来的 page_url_generator
req = requests.get(url)
req_text = req.text
tree_html = lxml.etree.HTML(req_text) #实例化lxml.etree.HTML对象
url_list = tree_html.xpath('//h2[@class="post-title"]/a/@href') #xpath 提取这个页面里面所有的软件详情页地址
yield url_list
def page_parser(url):
detail_url = url
req = requests.get(detail_url)
req_txt = req.text
html = bsp(req_txt,'lxml')
soft_name = html.find_all(attrs={"class":"post-title"})[0].string
tree_html = lxml.etree.HTML(req_txt)
date = tree_html.xpath('//div[@class="post-date"]/text()[2]')[0]
soft_url = re.findall('https://uploadproper\.net\/\w{12}',req_txt,re.S)[0]
detail_text = tree_html.xpath('//div[@class="entry"]/p//text() | //div[@class="entry"]/h2//text() | //div[@class="entry"]/h3//text() | //div[@class="entry"]/h4//text() | //div[@class="entry"]/h5//text() | //div[@class="entry"]/ul//text()')
category = html.find_all(attrs={"rel":"category tag"})[0].string + ' / ' + html.find_all(attrs={"rel":"category tag"})[1].string
try:
img = tree_html.xpath('//figure/img/@src | //h2/img/@src | //p/img/@src | //div/img[@class="aligncenter wp-image-343 size-medium"]/@src | //p/a/img/@src')[0]
info_list = [soft_name,date,category,img,soft_url,detail_text]
except IndexError:
img = '异常导致,请自行手动获取'
info_list = [soft_name,date,category,img,soft_url,detail_text]
return info_list
if __name__ == "__main__":
i = 1
category = input('请输入分类:')
pages = page_url_generator(category)
for url_list in soft_url_generator(pages):
for url in url_list:
with open('info.csv','a',encoding='utf-8') as f:
writer = csv.writer(f)
sim = page_paser(url)
print(sim)
writer.writerow(sim)
if url_list.index(url)==len(url_list)-1:
print('第'+ str(i) +'页爬取完毕')
i = i+1
项目总结
- 采用面向过程开发
- 应用生成器,进行了性能优化
- 待优化:采用多线程,可大大缩短采集时间
- 待优化:实现增量更新爬取



评论 (0)