

一、综述
这是站长的第一个Python网络爬虫项目实战,利用Python的requests库和正规则库对猫眼网站的Top100排行进行爬取。涉及到的关键知识点有四点:
- Python 中 requests 库的使用。
- 利用 re 库(正规则库)对请求到的网页进行解析,并提取目标内容。
- json格式文件存储和读取方法。
- 了解重构在开发中的作用。
二、准备工作
开始之前我们需检查 requests 库是否已经正确安装好了。如若没有请按照以下要求进行安装和检查:
安装:在终端中输入
pip3 install requests
检查是否正确安装:
fly@mazhixiangs-MBP ~ % python3
Python 3.7.6 (default, Dec 27 2019, 09:51:21)
[Clang 11.0.0 (clang-1100.0.33.16)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import requests
>>>
三、抓取分析
抓取的目标站点 url = 'https://maoyan.com/board/4'访问页面如下图所示:
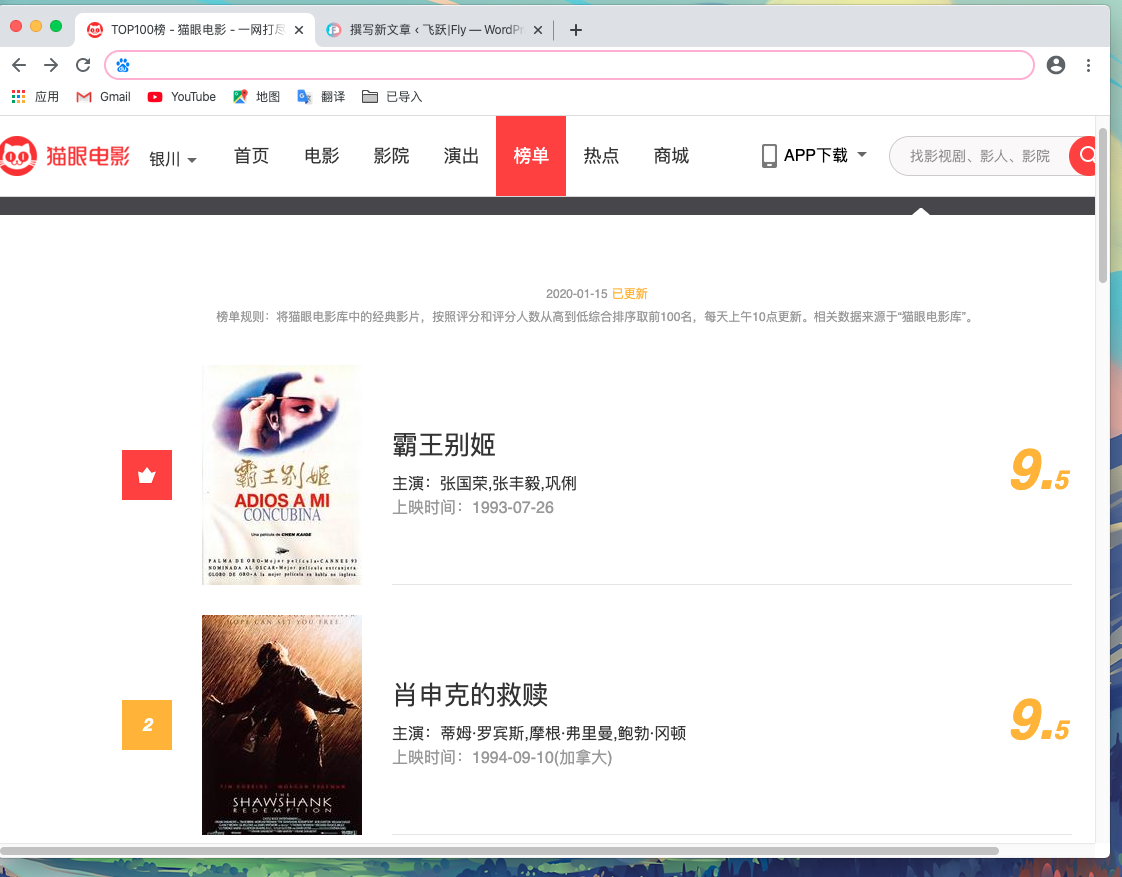
我们可以看到页面进行了分页,那么这是一种反爬措施。下面我们分析一下:
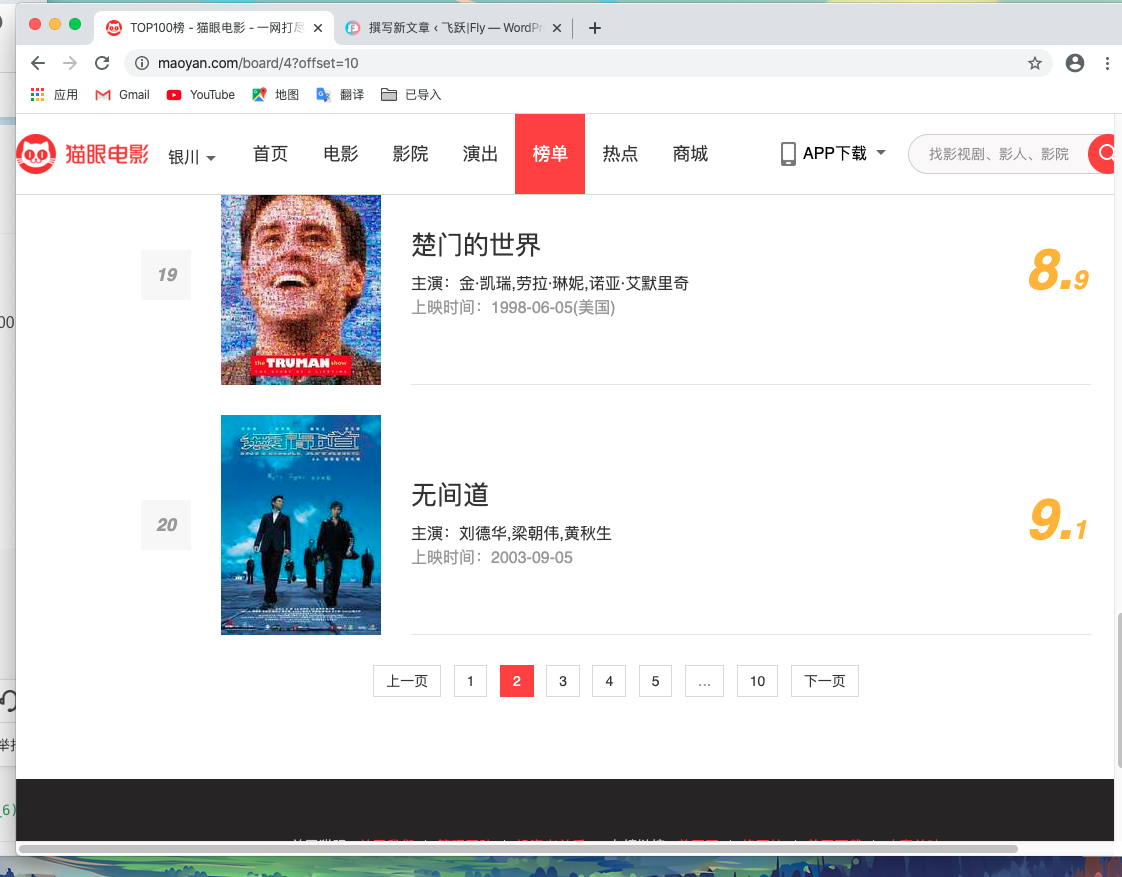
当点击第二页时,页面的URL发生了变化:url2 = 'https://maoyan.com/board/4?offset=10'比之前的URL多了一个参数:params = 'offset=10',而且页面显示的排行榜的11-20名的电影。继续点击第三页:url3 = 'https://maoyan.com/board/4?offset=20'参数offset=30,而显示的是21-30名的电影。
由此可以做出总结:
猜想:
offset这个参数代表偏移量,如若offset=n,(n = 0,10,20,30……)则相应页面显示的电影范围应为:(n+1,n+10)。
验证:
url = 'https://maoyan.com/board/4'显示的是1-10的电影,则可推出offset=0,则不显示;url2 = 'https://maoyan.com/board/4?offset=10'显示的是11-20的电影,则可推出offset=10;url3 = 'https://maoyan.com/board/4?offset=20'显示的是21-30的电影,则可推出offset=20;
由此可以看出我们的推测是正确的。这样抓取这Top100的电影只需将offset循环到90即可。抓取不同的页面后再用正则表达式处理即可。下面我们实现抓取一页的代码:
四、抓取一页
import requests
from requests.exceptions import RequestException
def get_one_page(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36',
'Cookie': '__mta=20281991.1579054760901.1579064616380.1579065114783.4; uuid_n_v=v1; uuid=6F3F3ED0373D11EA807E4F280ED9928C092CC249433244F59FBE8669FCFA2E50; _csrf=bc2c69be4d336bfd2624b0c6f6f1624c87f6bb56cf5858cf47f2ef512c1f0a15; mojo-uuid=d01a035c04286ed76b4910f8739e3c7d; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1579004882,1579054760; _lxsdk_cuid=16fa6ff832ec8-0d6373886d4491-39627c0f-1fa400-16fa6ff832ec8; _lxsdk=6F3F3ED0373D11EA807E4F280ED9928C092CC249433244F59FBE8669FCFA2E50; mojo-session-id={"id":"bfb6d2e157ffc93b13c24914f1408623","time":1579064614757}; mojo-trace-id=4; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1579065114; _lxsdk_s=16fa795df6a-049-42-4b5%7C%7C5'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def main():
url = 'https://maoyan.com/board/4'
html = get_one_page(url)
print(html)
main()在这一页中实现了get_one_page()方法参数为URL。这样就可以得到第一页的网页源代码了,下面我们需要对网页进行解析,提取有用信息。
五、解析一页源代码(正则表达式,正则库的使用)
下面我们来观察下页面的结构:
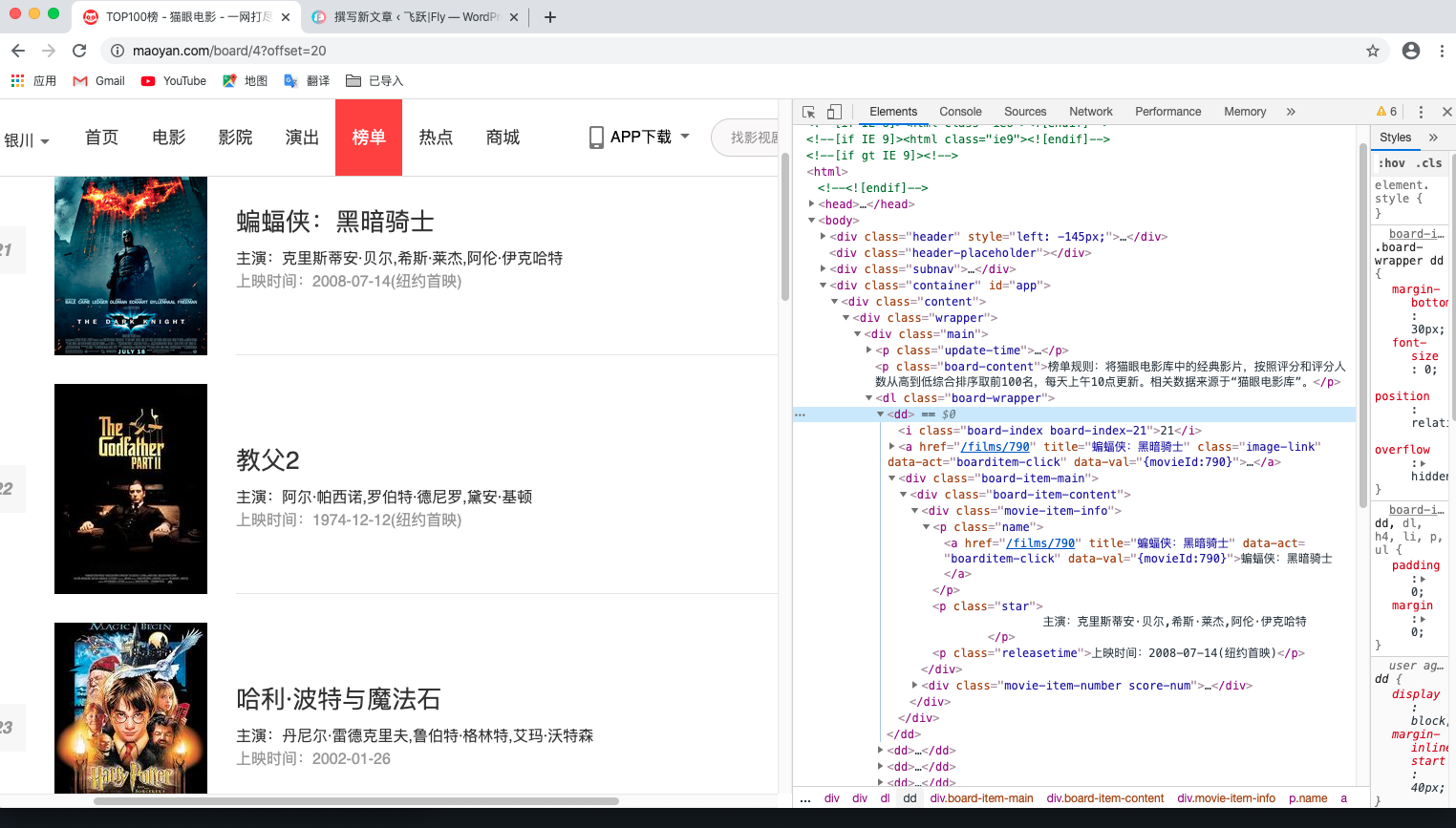
可以发现一部电影的信息包含在 dd 节点内,下面我们用正则表达式来提取各部分信息:
- 排名信息:包含在 class 为board-index的 i 节点内 用非贪婪的方式来进行匹配
<dd>.*?board-index.*?>(.*?)</i> - 图片信息:可以看到后面有 a 节点 a 节点里面又包含两个 img 节点。第二个 img 节点的 data-src 属性是图片的链接,我们来匹配这个属性。改写如下:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)" - 电影名称:它在后面的 p 节点内,class 为 name 可利用 name 作为标志进一步来提取后面 a 节点内的电影名称。改写如下:
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a> - 主演、发布时间、评分等内容:
<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a' + '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>
解析代码如下:
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'
+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
说明:
- re.S:为正则修饰符,匹配换行符。
- .findall():该方法会搜索整个字符串,然后返回匹配正则表达式的所有内容,在本段中会扫描"html"然后匹配结果。
- .comile():该方法会将正规则字符串编译成正则表达式对象,以便在后面的匹配中复用。在本段中因为我们要匹配10条这样的信息所以用到了它。
- yield关键字:yield就是 return 返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后开始。这个关键字给出一个例子:
def fun():
print("starting…")
while True:
res = yield 10
print("req:",req)
n = fun()
print(next(n))
print("*"10)
print(next(n))
输出:starting…
4
**********
res: None
4
解释:
1.程序开始执行以后,因为fun函数中有yield关键字,所以fun函数并不会真的执行,而是先得到一个生成器n(相当于一个对象).
2.直到调用next方法,fun函数正式开始执行,先执行fun函数中的print方法,然后进入while循环.
3.程序遇到yield关键字,然后把yield想想成return,return了一个10之后,程序停止,并没有执行赋值给req操作,此时next(n)语句执行完成,所以输出的前两行(第一个是while上面的print的结果,第二个是return出的结果)是执行print(next(n))的结果.
4.程序执行print("*"*10),输出10个*.
5.又开始执行下面的print(next(n)),这个时候和上面那个差不多,不过不同的是,这个时候是从刚才那个next程序停止的地方开始执行的,也就是要执行res的赋值操作,这时候要注意,这个时候赋值操作的右边是没有值的(因为刚才那个是return出去了,并没有给赋值操作的左边传参数),所以这个时候req赋值是None,所以接着下面的输出就是req:None.
6.程序会继续在while里执行,又一次碰到yield,这个时候同样return 出10,然后程序停止,print函数输出的4就是这次return出的10.
六、写入文件
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')说明:
- 将提取结果写入文件中.
- 利用json库的dumps()方法实现字典的序列化,并指定ensure_scii参数为False,此举保证了输出结果是中文形式而不是Unicode编码.
- 调用write_to_file()方法实现字典写入文件的过程.
七、整合代码、多页爬取
完整代码如下:
import json
import requests
from requests.exceptions import RequestException
import re
import time
def get_one_page(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36',
'Cookie': '__mta=20281991.1579054760901.1579064616380.1579065114783.4; uuid_n_v=v1; uuid=6F3F3ED0373D11EA807E4F280ED9928C092CC249433244F59FBE8669FCFA2E50; _csrf=bc2c69be4d336bfd2624b0c6f6f1624c87f6bb56cf5858cf47f2ef512c1f0a15; mojo-uuid=d01a035c04286ed76b4910f8739e3c7d; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1579004882,1579054760; _lxsdk_cuid=16fa6ff832ec8-0d6373886d4491-39627c0f-1fa400-16fa6ff832ec8; _lxsdk=6F3F3ED0373D11EA807E4F280ED9928C092CC249433244F59FBE8669FCFA2E50; mojo-session-id={"id":"bfb6d2e157ffc93b13c24914f1408623","time":1579064614757}; mojo-trace-id=4; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1579065114; _lxsdk_s=16fa795df6a-049-42-4b5%7C%7C5'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'
+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
for i in range(10):
main(offset=i * 10)
time.sleep(1)八、重构代码
在大型项目中,经常需要在添加新代码前重构既有代码。重构旨在简化既有代码的结构,使其更容易扩展。前边的整合代码中我们已经把各部分功能实现了函数模块化,那么下面我们就把各部分抽离出来,把这些函数封装为一个个的模块,并创建一个"maoyan_main.py"模块然后把其他模块集成到这个模块。
maoyan_main.py
import time
import maoyan_post
import maoyan_save
import maoyan_parse
def main(offset):
url = 'http://maoyan.com/board/4?offset=' + str(offset)
html = maoyan_post.get_one_page(url)
parse = maoyan_parse.parse_one_page(html)
for item in parse:
maoyan_save.write_to_file(item)
if __name__ == '__main__':
for i in range(10):
main(offset=i * 10)
time.sleep(1)maoyan_post.py
import requests
from requests.exceptions import RequestException
def get_one_page(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36'
'Cookie': '__mta=20281991.1579054760901.1579064616380.1579065114783.4; uuid_n_v=v1; uuid=6F3F3ED0373D11EA807E4F280ED9928C092CC249433244F59FBE8669FCFA2E50; _csrf=bc2c69be4d336bfd2624b0c6f6f1624c87f6bb56cf5858cf47f2ef512c1f0a15; mojo-uuid=d01a035c04286ed76b4910f8739e3c7d; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1579004882,1579054760; _lxsdk_cuid=16fa6ff832ec8-0d6373886d4491-39627c0f-1fa400-16fa6ff832ec8; _lxsdk=6F3F3ED0373D11EA807E4F280ED9928C092CC249433244F59FBE8669FCFA2E50; mojo-session-id={"id":"bfb6d2e157ffc93b13c24914f1408623","time":1579064614757}; mojo-trace-id=4; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1579065114; _lxsdk_s=16fa795df6a-049-42-4b5%7C%7C5'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return Nonemaoyan_parse.py
import re
def parse_one_page(html):
pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'
+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'actor': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}maoyan_save.py
import json
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n')
这样一来既避免了项目源代码更长,并使得项目的逻辑更容易理解且也使得项目有层次体系,使得后期扩展维护更加容易。
这就是本次项目的所有内容,预告一下:下期实战项目是天科大教务系统,主要实现两个功能:
1.查询成绩
2.选课功能
即飞跃产品的第4个产品:飞跃校园|Fly-College


评论 (0)